Professor Hugh Craig caps a 40 year career as Professor Emeritus
Professor Hugh Craig – a pioneer of the digital humanities in Australia, a generous teacher and mentor and one of… Read more

Intelligent Archive (IA) is a Java application for managing corpora of texts for stylometry. It builds on a long history of world-leading stylometry research at the Centre for Literary and Linguistic Computing (CLLC), University of Newcastle, Australia.
Intelligent Archive is hosted with the Centre For 21st Century Humanities. DOWNLOAD
The CSF is an initiative of the Australian e-Humanities Network. It was created by the Centre for Literary and Linguistic Computing at the University of Newcastle, NSW, Australia. The project was funded by the Australian Research Council through a Learned Academies Special Projects grant. Design and programming is by Russell Whipp.
The Computational Stylistics Facility presents a set of Shakespeare play texts with a ready-made apparatus for computational-stylistics exploration. Within its parameters, users can define any number of variations on what is analysed and how. The system has been designed for use by those with no experience in computational stylistics, and is set out so as to work intuitively as far as possible.
The texts can be analysed as whole plays, blocks, i.e. sequential segments of plays, or as character parts. Word-variables for the analyses can be typed or pasted in, or the system can calculate for you the 20, 50, or 100 most common words of the whole set or the sub-set of texts you are using. The best way to start is with a simple walk-through. Four are offered below.
Fuller instructions are in the CSF manual which you can download here. You may also like to consult a recent poster presentation on the CSF.
(Note that when navigating back to re-run any analysis, you need to "Remove all" of your play or character selections, and "Clear" your word selections in order to start afresh.)
Statistical Analysis has long been employed in the study of literary texts and has tended, for obvious reasons to concentrate on the most common or the most uncommon of the linguistic phenomena they display. The discovery, by Burrows, on which much of our work rests is that the frequency-patterns of all the most common words, whatever they may be, are so distinctive, stable, and closely interlocked that they reveal more when they are examined together than when any of them is examined in isolation.
After ten years work, we are able to form useful inferences, at an extremely high level of probability, from almost any comparative study of two or more sets of texts and, upon that basis, to predict how further texts will behave. Such comparisons may reflect change over time or differences of literary form within the writings of a single author; characteristic differences between two or more authors; and larger "class-differences" between different groups of authors. These last include consistent and intelligible differences between eighteenth, nineteenth, and twentieth century authors; between male and female authors; and between Australian and non-Australian authors. In a related line of inquiry, we find that it is possible to detect systematic differences between those texts where one author revises the work of another and those where, starting with a clean sheet, one author imitates the work of another.
Our main and most usual procedure is first to establish frequency tables for the thirty, fifty, or hundred most common words–whatever they may be–of a given set of texts; to extract a correlation matrix; and to subject the matrix to principal components analysis. If there are consistent resemblances and differences between some of the texts and others, the first two or three principal components of the correlation-matrix allow the texts to form into clusters. In a second phase of the operation, the frequency tables are subjected to distribution tests (like Student's t-test and the Mann-Whitney test) to determine just which words play most part in separating the texts in the manner previously observed. The relationship between the clustering of the texts and the patterning of those words that show statistically significant differences between the clusters of texts thus makes it possible to consider what linguistic factors are at work. In a third phase, those words that satisfied the distribution tests are used in a fresh analysis of the original set of texts and of texts not hitherto considered: if the previously formed clusters reflect a true difference between populations, the texts now added should take predictable positions.
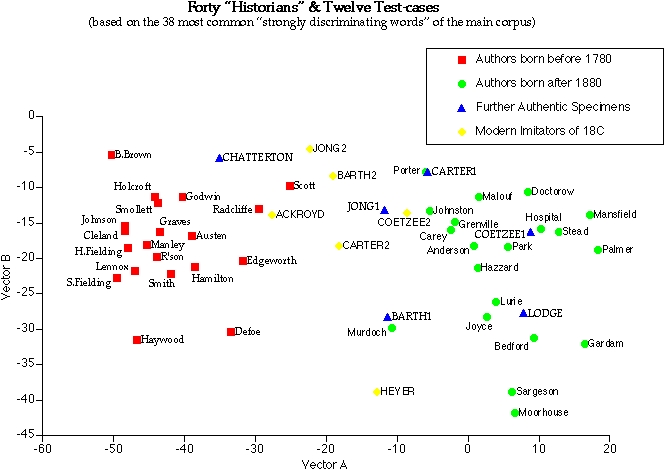
Figure 1 shows a good but not exceptional result. In the first of the phases sketched above, forty authorial sets of texts (each set consisting of at least three texts, all of them first-person retrospective narratives of a kind known in the eighteenth century as a "history") were compared. They formed two clusters in which the twenty eighteenth-century writers stood far from the twenty writers of our own century. The hundred most common words were then subjected to the two distribution tests in an attempt to establish which words most influenced this separation. Thirty-eight words satisfied both tests at levels above 0.001, indicating probabilities (for each word) of less than one chance in a thousand that the two clusters did not come from different populations. The analysis was then repeated, with two changes: only the thirty-eight "strongly discriminating" words were used; and twelve fresh authorial sets were added. Six of these are authentic eighteenth and twentieth-century work by Thomas Chatterton, on the one hand, and by David Lodge, John Barth, Angela Carter, J M Coetzee, and Erica Jong on the other. The remaining six sets–by the four novelists last-named and by Peter Ackroyd and Georgette Heyer–all represent texts in which modern writers attempt to imitate the work of their eighteenth or early nineteenth-century forebears. As Figure 1 shows, the two main clusters are quite discrete and the test cases behave according to prediction: the authentic cases lie within or close beside the appropriate clusters; and, though they differ considerably from each other, none of the attempted imitations penetrates the target group. The value of specimens like this, where the truth is already known, is in testing procedures for use in cases where it is not.
Fiction from 1700

Professor Hugh Craig – a pioneer of the digital humanities in Australia, a generous teacher and mentor and one of… Read more

Credited with an important Shakespeare discovery, UoN alumni and conjoint member of the Centre for Literary and Linguistic Computing, Dr… Read more

UON’s Centre for Literary and Linguistic Computing (CLLC) is behind a move to create a new partnership between stylometry labs… Read more

After completing his first degree in India in computer science, then a PhD in computational stylometry in Malaysia, Ahmad Alqurneh… Read more

Professor Hugh Craig has been awarded a Discovery Projects grant by the Australian Research Council for his project: 'Folio Shakespeare… Read more

The University of Newcastle acknowledges the traditional custodians of the lands within our footprint areas: Awabakal, Darkinjung, Biripai, Worimi, Wonnarua, and Eora Nations. We also pay respect to the wisdom of our Elders past and present.



{kind=link}